정의
ZFS는 현재 최강의 파일시스템이라고 불린다. 이유는 다음과 같다.
- 최초의 128비트 파일 시스템 : 2^28QiB (약 3백17경 TB)의 용량을 지원한다. 현 세대 스토리지 기술을 감안하면 그냥 무한대라고 할 수 있다.
- 네트워크 지원 : NFS, iSCSI, CIFS(SMB)등을 지원한다.
- SSD 캐시 지원
- 자체 RAID 지원
- Pool 기능 지원
- Silent Corruption 방지
아래는 ZFS 스토리지 풀의 구조이다.
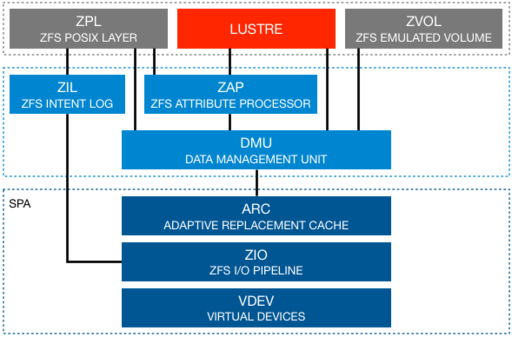
ARC
ARC는 Adaptive Replacement Cache의 약어로 최근에 읽거나 쓴 파일들이 1차적으로 위치하는 저장공간이다. cache로서 ZFS가 메모리를 엄청나게 쓰는 주요 원인이 이 ARC이다.
ZFS는 ARC의 내용물을 단순히 최근에 읽거나 썼다, 접근 횟수가 많다 뿐만 아니라 Hit Ratio에 따라 내용물을 스스로 조절하는 메커니즘을 가지고 있다.
기본적으로 램디스크로 주 메모리를 잡아 사용하기 때문에 휘발성이며, 매우 빠르고 기가당 비용상 결코 저렴한 저장소가 아니기 때문에 크기가 한정적이 될수밖에 없다.
이런 Hit Ratio와 용량의 한계를 극복하기 위한 2차 cache가 후술될 L2ARC다.
VDev
vdev는 Virtual Device(가상 장치)의 약어지만 꼭 가상 장치를 뜻하는 것은 아니다. vdev는 zpool을 구성하는 요소로서 zpool과 물리적인 디스크 사이에 존재하는 하나의 추상화된 계층이다.
예를 들어 흔히 우리가 아는 RAID로 형성된 가상 장치 등이 여기에 대응된다. 소프트웨어 RAID와 관련된 ZFS의 vdev에는 다음과 같은 종류들이 있다.
- Stripe : RAID0 스트라이프 구성이다.
- Mirror : RAID 1 미러링 구성이다.
- raidz1/2/3 : 간단하게 말하면 동일한 크기의 디스크가 묶인 기준으로 패리티 용량을 디스크 1/2/3개씩 두는 RAID 구성. 앞의 두 개는 각각 RAID 5/6에 대응된다.
- spare : “핫 스페어”라고도 불리며, 평상시에는 아무 것도 하지 않는 여분의 상태로 남겨져 있다. 그러다가 다른 raidz1/2/3의 구성 디스크 중에 결함이 생기면 그 디스크가 이 스페어 디스크로 자동으로 대체된다.
- cache : cache는 L2ARC로 쓰이는 vdev를 말한다. L2ARC(Level 2 ARC)는 시스템의 RAM에 거주하는 캐시인 ARC의 보조로서 동작한다. 짧게 말하면 읽기 캐시로서, 순위가 높은 데이터들을 ARC에 올리고 그 외의 데이터들을 L2ARC로 넣게 된다.
만일 ARC에서 원하는 데이터를 찾지 못하면(ARC의 예측 실패) L2ARC에서 원하는 데이터를 찾고, 또 실패하면(L2ARC의 예측 실패) 그제서야 비로소 zpool을 구성하는 데이터 디스크에 접근해 원하는 데이터를 찾아가게 된다. 당연한 말이지만 L2ARC 또한 zpool을 주로 구성하는 하드 디스크보다 훨씬 빠른 SSD 등을 주로 이용해야 한다. 다만 SLOG에 비해 L2ARC로 얻을 수 있는 성능의 향상은 I/O가 엄청 잦고 부하가 큰 환경이 아니면 적은 편이다. L2ARC는 주로 임의의 위치를 읽는 데이터베이스 등에서 유용하며, 같은 부분이 반복해서 주로 읽히는 경우에 쓰이고, 순차읽기 등에서는 L2ARC로 얻을 수 있는 성능 이득이 없다.
또한 ZFS는 L2ARC의 체크섬 값 등을 보관할 공간을 다시 RAM에 할당하게 되므로, RAM에 비해 너무 L2ARC가 클 경우 RAM 용량이 부족해 스왑이 발생해 도로 성능이 떨어지는 역효과가 일어난다. 보통 시스템 RAM 용량이 64GB 이상은 되어야 L2ARC를 고려할 만하다.
- loglog는 SLOG(Seperate intent LOG)를 말한다.SLOG를 알기 전에 앞서 ZIL(ZFS Intent Log)란 것을 알 필요가 있다. ZIL이란 하드 디스크에 직접 기록되기 전에 앞서 데이터가 먼저 기록되는 쓰기 캐시로서 ZIL로 할당된 용량은 zpool의 저장 가능 용량에 반영되지 않으며 순수히 캐시 용도로만 이용된다. ZFS는 zpool마다 반드시 ZIL이 있다. 보통 하드웨어 RAID 컨트롤러의 경우 이런 쓰기 캐시가 반드시 컨트롤러 내에 존재하지만 ZFS 구성 하드웨어에는 이러한 캐시는 옵션 사항으로써, 반드시 이러한 전용 쓰기 캐시 메모리가 제공된다는 보장이 없다.
이런 경우 ZFS는 zpool의 일부를 ZIL로 할당해 사용한다. 하지만 이 경우 보통 하드 디스크로 구성되는 zpool 특성상 zpool 자체의 탐색 속도가 느릴 수 있으며 zpool의 입출력이 잦은 경우 성능이 떨어지게 된다.본래 디스크 쓰기 작업은 두 종류로 분류된다. 동기 쓰기와 비동기 쓰기이다.
먼저 쓰기 작업이 수행되면 운영 체제는 데이터를 먼저 RAM 상의 캐시에 기록한다. 그리고 여기서 비동기 쓰기 작업의 경우 RAM 캐시에 기록된 것까지만 확인한 후 프로그램은 다음 명령을 수행하러 넘어간다. 즉, 플래시 메모리든 하드 디스크든 어딘가에 실제로 데이터가 기록되지 않고 넘어간다. 쓰기 명령 수행 사항과 실제 디스크 상의 데이터가 일치(즉 동기)하지 않을 수 있다. 그래서 이 쓰기 작업을 비동기 쓰기라고 한다. 비동기 쓰기는 느리디 느린 디스크가 작업을 완료할 때까지 프로그램이 다음 명령을 수행하지 않고 대기하지 않게 되므로 프로그램의 실행 속도가 빨라진다. 그러나 예상치 못한 상황(대표적으로 정전) 등이 발생한다면, 비동기 쓰기의 경우 아직 그 내용이 디스크에 기록되지 않았다면 당연히 그 내용은 소실되는 문제가 있다. 이로 인해 비동기 쓰기의 경우 프로그램 상에서 실제로 디스크에 데이터가 기록되었는지 확인하는 작업이 필요하다. 반면, 동기 쓰기의 경우 RAM 캐시에 기록하는 것까지는 동일하지만 이로 끝나지 않고 실제로 SSD나 하드 디스크 등의 비휘발성의 안정된 저장장치에 대해 기록되는 작업까지 그대로 수행한다. 이 쓰기 작업이 완수될 때까지 프로그램은 다음 명령을 수행하지 않고 대기한다.
그래서 동기 쓰기의 경우 쓰기 명령을 했다면 그 명령이 완수되었다면 그 데이터 내용은 반드시 디스크에 기록되었음이 보장된다. 즉, 쓰기 명령 수행사항과 실제 디스크 상의 데이터가 일치(동기)하므로 동기 쓰기라고 한다. 동기 쓰기는 이런 장점이 있지만, 반대급부로 느린 디스크의 기록 작업이 끝날 때까지 기다려야 하므로 프로그램의 수행 속도가 그만큼 늦어지게 된다. 이제 여기서 ZFS SLOG가 그 기능을 발휘한다.
POSIX 규격에 따르면 동기 쓰기는 비휘발성의 안정한 디스크에 그 내역이 기록되기만 하면 그 조건을 만족한다. 그래서 ZFS는 SLOG가 제공되면 동기 쓰기로 주어진 내용을 먼저 SLOG에 기록한다. SLOG는 비휘발성 메모리이므로 동기 쓰기의 조건이 충족되고 따라서 느린 하드 디스크까지 기록을 완료할 필요가 없다. 프로그램은 다음 명령을 계속 수행하고 SLOG에 기록된 데이터 변경 사항은 이후 하드 디스크에 반영된다. 즉, 동기 쓰기가 비동기 쓰기처럼 동작하게 되는 것이다.당연한 말이지만 이 때 SLOG로 쓸 매체는 하드 디스크보다 빠른 SSD가 권장된다. 또한 별도의 매체가 전용 쓰기 캐시로 할당되므로 입출력을 분산된다. 그리고 SLOG를 쓰게 될 경우 ZFS의 디스크 파편화를 줄이는 효과도 있다. 단, SLOG 장비가 만일 고장날 경우, v19 혹은 그 이전의 zpool의 경우 그 zpool 전체가 소실되는 단점이 있었고 SLOG로 할당하는 장비를 미러링으로 묶어 SLOG 장비의 고장에 대비하는 방법을 썼다. 그 이후 버전의 zpool에서는 이 단점은 사라졌다. 단지 SLOG 장비가 소실되면 SLOG 장비가 제공하던 성능 향상만이 사라질 뿐이다. 그래도 여전히 SLOG 장비 미러링은 성능 유지를 위해 유효한 전략이다.
여기서 vdev의 구성 요소로 다른 vdev가 들어갈 수 있다. 예를 들어 RAID 10와 같은 구성을 위해서는 mirror 2개로 구성된 stripe를 만들면 된다.또한 ZFS는 파일 시스템 자체에서 RAID를 지원하기 때문에, 몇 가지 특징을 보인다.
- Resilvering 시간 감소 : RAID의 리실버링 등을 할 때 원래 데이터가 적게 들어 있을 경우 시간이 훨씬 줄어들게 된다. 기존의 RAID 솔루션들은 파일 시스템과 분리되어 있기 때문에, 블록 단위까지만을 관리하며 따라서 그 블록 내의 데이터가 어떤 방식으로 기록되는지는 전혀 모르므로 어떤 블록에 데이터가 기록되어 있는지 아닌지를 알수 없다. 그래서 리실버링 작업을 하게 되면 디스크의 처음부터 끝까지를 모두 다 검사하여 복원해야 하므로 몹시 시간이 오래 걸린다. 그러나 ZFS는 그 자체가 곧 파일 시스템이므로 정확하게 어느 부분만 리실버링 작업이 필요한지 알 수 있으며 따라서 리실버링의 작업 시간이 획기적으로 줄어든다. 예를 들어 zpool을 구성하고 있던 데이터 디스크 하나가 케이블의 문제로 잠시 분리되었다가 정비 후 다시 연결된 경우, 그 잠깐의 분리 작업간에 발생한 변동 사항에 대해서만 리실버링을 할 수 있어 단 몇 분만에 리실버링이 끝난다. 그러나 다른 RAID의 경우 이 때 디스크의 시작부터 끝까지 모두 훑어내리는 수 밖에 없어 엄청난 시간이 소요된다.또한 용량이 10% 정도만 차 있는 RAID의 경우 기존의 RAID 솔루션은 역시 디스크의 처음부터 끝까지 쭉 구별없이 모든 블록을 작업해야 하지만, ZFS의 경우 기록된 데이터가 기록된 10%의 블록에 대해서만 작업을 하므로 작업 시간이 1/10로 줄어든다.
Zpool
zpool은 기존의 파일 시스템과 컨셉 자체가 꽤 다르며 NTFS나 HFS 등의 기존 파일 시스템의 파티션과 볼륨 사이에 놓인 레이어 계층이다. 다만 ZFS 볼륨이라고도 불리기도 하지만 여기서는 zpool로 통일해서 언급한다. 먼저 ZFS는 각 하드 디스크에서 사용할 GPT 파티션들을 구성원으로 가상 하드웨어인 vdev들을 만든다. 그리고 이 vdev들을 원하는 것끼리 다시 묶은 것이 zpool이다. 이러한 구조를 통해 ZFS는 별도의 RAID 컨트롤러가 없이도 소프트웨어 RAID를 파일 시스템 자체에서 직접 안정적으로 정의할 수 있다. 예를 들어 하나의 zpool은 HDD 6개가 묶인 vdev인 raidz2 + SLOG 장비로 SSD 2개가 미러링으로 묶인 mirror로 구성될 수 있다. 이렇게 구성된 zpool은 각 구성 디스크가 꽂힌 포트가 바뀌어도 정상적으로 각 디스크를 식별해 zpool을 유지하며 다른 컴퓨터로도 손쉽게 zpool을 옮길 수 있다.
RAID 모드로는 stripe, mirror, raidz, raidz2 등을 지원하는데 RAID로 따지자면, 각각 raid0, raid1, raid5, raid6와 동일하다. 그런데 이뿐만 아니라 zpool의 구성원으로 디스크를 SLOG(흔히 ZIL로도 불림), L2ARC를 추가할 수 있다.
Dataset
이 dataset이 바로 일반적인 파일 시스템의 볼륨에 대응되는 부분이다. 그러나 dataset은 우리가 흔히 아는 볼륨과는 확연히 다르다. 먼저 dataset은 우리가 흔히 아는 파티션과 달리 물리적인 특정한 공간에 고정되지 않는다는 점이다. 먼저, 컴퓨터의 파일 시스템은 하드 디스크가 실제로 어떻게 생겼는지(플래터가 몇 장인지, 모터가 몇 개인지 등등...)는 모르며, 단지 첫번째 블록부터 n 블록이 일렬로 늘어서 구성된, 1차원적인 공간으로 인식한다는 점부터 알아야 한다. 그리고 하드 디스크의 파티션은 정확하게 a번째 블록~b번째 블록까지의 하나의 구간이란 형태로 지정한다. 그래서 이 파티션들은 이 1차원적인 공간에서의 특정 구간에 정확하게 1:1 대응되는 구조이며, 또한 각 NTFS, FAT, exFAT 등의 볼륨은 각 파티션에 정확하게 1:1 대응한다. 이로 인해 우리가 흔히 쓰는 Windows 등의 OS 에서는 디스크 볼륨을 확장해야 할 일이 있을 때 만일 그 볼륨이 위치한 파티션의 여유 공간이 만일 없다면 반드시 먼저 어떤 파티션이 끝나는 지점으로부터 늘려야 할 공간만큼의 구간이 텅 비었는지 확인하고, 비지 않았다면 그 곳의 데이터를 딴 곳으로 이동시키는 작업이 반드시 필요하다. 그리고 위의 1:1 대응되는 구조로 인해 파티션의 구간을 그 시작 지점에서부터 앞으로 확장시키는 것은 외부 프로그램을 동원하지 않는 이상 불가능하다.
그러나 ZFS는 전혀 구조가 다른데, zpool 안에 여러 개의 dataset이 존재하게 된다. dataset은 마치 파일 디렉토리와 비슷하게 또 다른 dataset 안에 위치할 수도, 그렇지 않을 수도 있다. 기존의 파일 시스템이라면 전혀 꿈도 꿀 수 없는 구조인 것이다. 그리고 위에서 말한대로 물리적인 위치에 붙박히지 않은 특징 때문에 크기의 조절이 매우 자유롭다. dataset의 용량을 늘이는 것도 줄이는 것도(물론 dataset 내의 여유 용량만큼만) 명령을 주는 거의 즉시 바로 완료된다.
그리고 dataset은 스냅샷 기능을 지원한다. 스냅샷이란 어떤 dataset의 어떤 시점에서의 정적 상태를 기억해두는 기능으로, 원한다면 언제든지 그 스냅샷의 상태로 특정 dataset을 복원시킬 수 있는 기능이다. 그리고 이 기능은 몹시 빠르게 가볍게 동작하여 스냅샷을 저장할 때나 특정 스냅샷으로 복원할 때나 거의 명령을 내리는 순간 작업이 완료된다. 거기다가 dataset 전체의 상태를 저장했는데도 스냅샷 직후에는 용량도 몇백 바이트 정도밖에 먹지 않는다. 이는 ZFS가 dataset에서 Copy-on-Write라는 기록 방법을 쓰기 때문에 가능한 일이다. 특정 dataset의 스냅샷을 저장할 경우 그 dataset의 그 스냅샷 이후에 일어나는 파일의 삭제, 변경 등의 수정 작업으로 발생한 변경 부분은 그 데이터의 원본에 덮어써지지 않고 다른 곳에 기록된다. 그리고 현재 시점의 그 dataset을 읽을 때는 변경되지 않은 부분은 원본 부분을 그대로 읽어내고, 그 변경 지점을 읽을 때만큼은 그 다른 곳에 기록된 사본을 참조하는 식이다. 이렇게 한다면 스냅샷을 저장한 이후 추가로 발생하는 용량 소모는 변경된 부분의 용량만큼만 될 뿐, 일일이 dataset 전체의 크기만큼의 사본이 생성될 필요가 없어진다. 물론 복원할 때도 간단하다. 특정 시점으로 복원할 때, 그 특정 시점 이후에 발생한 모든 변경 사항 부분만 삭제해 버리면 바로 원본으로 복원되는 것이다. 그리고 스냅샷 기능은 일정 주기에 맞춰 자동으로 스냅샷을 저장하는 기능도 있으며, 이를 이용하면 주기적으로 각 dataset의 상태를 저장한 뒤 문제가 생기면 바로 복원해 해결할 수 있다. 예를 들어 중요한 자료가 담긴 documents란 이름의 dataset을 5분 단위로 스냅샷을 찍게 한 뒤 자신이 실수로 문서를 삭제해버리는 상황이 발생해도 단 5분의 작업량만큼의 손실을 보는 것으로 끝내버릴 수도 있다. 또는 네트워크 상으로 공유해뒀던 파일 또는 디렉토리가 랜섬웨어에 감염되었더라도 이 스냅샷 기능을 이용한다면 랜섬웨어의 조작이 가해지기 바로 이전의 스냅샷 시점으로 바로 복원해 아무 일도 없었던 것처럼 만드는 것도 가능하다.
그 외에도 dataset에서는 실시간 데이터 압축 기법도 제공된다. 먼저 흔히 우리가 아는 그 파일 압축 기법이 있다. 압축 방법으론 gzip, lz4 등이 있다. 실제로 데이터를 기록할 때 압축을 한 차례 거친 후 기록하는 방식이다. 그런데 이 것 말고도 ZFS에서 지원하는 또 다른 압축 기법으로 deduplication이란 기법이 있다. 이 deduplication이란, 만일 동일한 내용을 가진 블록이 여럿 존재한다면 실제로는 그 블록들 중 하나만을 남기고 나머지는 다 지운 뒤, 그 데이터를 읽을 때는 모두 그 블록을 참조하도록 기록해두는 기법이다. 이 때 블록의 동일성 여부를 검증하기 위해 암호학적으로 안전한 해시 알고리즘으로 그 체크섬을 비교하는 방식을 쓰며 만일 사용자가 원한다면 훨씬 간단하고 빠르지만 안전하지 않은 해시 알고리즘으로 1차 대조를 한 뒤 체크섬이 같다면 그 같은 블록간 1:1 비교를 해보는 옵션도 제공한다. 다만 이 deduplication은 충분한 하드웨어 사양이 보장되어야만 성능의 큰 저하가 발생하지 않으므로 조심스레 쓰는 것이 권장된다.
Zvol
ZFS는 dataset 말고도 zvol이라는 영역을 설정할 수 있다. dataset이 ZFS가 파일 레벨까지 관리하는 영역이라면, zvol은 그와 달리 ZFS가 블록 단위까지만 관리하는 영역이다. 이것이 의미하는 바는 곧 이 영역의 블록 내용이 어떤 형식으로 짜이든 상관없다는 뜻으로 zvol 영역은 NTFS나 HFS+ 볼륨 등으로 포맷해서 관리할 수 있다. 물론 ZFS 자체는 전혀 NTFS 볼륨을 전혀 이해하지 못하며, 따라서 보통 이 영역은 iSCSI를 통해 원격으로 다른 컴퓨터에 연결, 탑재되어 물리적으로 연결된 하드 디스크처럼 사용된다.
그리고 이러한 특성으로 인해 zvol은 dataset과는 달리 ZFS의 강점 중 하나인 스냅샷 기능이 지원되지 않는다. 그 외엔 zvol은 dataset의 특징을 모두 가지고 있다. 예를 들어 zvol 또한 정확하게 디스크의 특정 구간에 1:1 대응되는 영역이 아니므로, zvol 내의 데이터나 zpool의 용량이 허용하는 한 크기의 변화가 자유자재로 이루어질 수 있다.
Scrub
ZFS의 강점 중 하나는 Silent Corruption을 방지하는 기능이 있다는 점이다. 디스크에 기록된 데이터는 가만히 두더라도 자연 방사능 등의 영향으로 인해 비트가 뒤집히는 현상이 발생할 수 있다. 이런 데이터 변질은 그 발생 여부를 바로 검출할 수 없다는 점에서 위험하다. 또한 하드 디스크의 비트 당 변질 발생률은 거의 그대로인 반면, 하드 디스크의 용량은 계속 커지고 있기 때문에 이러한 변질의 발생률은 더욱 높아지고 있다. 데이터의 용량이 크면 클 수록 이런 위험성이 높은데, CERN(링크) 의 연구 결과에 따르면 6개월 넘게 97PB의 데이터를 처리했을 때 그 중 약 128MB의 데이터가 완전히 변질되었다고 한다.
ZFS에서는 scrub 명령을 제공하는데, 이 명령은 디스크의 모든 메타데이터와 데이터의 체크섬을 검사해 혹시나 발생했을 변질을 감지한다. raidz, raidz2, mirror 등 redundancy를 제공하는 vdev에서는 scrub으로 Silent Corruption이 감지되면 단순 감지로 끝나지 않고 자체적으로 잘못된 데이터를 정정한다. scrub은 여타 디스크 검사 도구와 달리 검사 대상인 파일 시스템을 오프라인으로 만들 필요가 없이 동작 중인 상태 그대로 검사를 진행할 수 있다. 다만 이 scrub 명령은 말 그대로 모든 데이터를 점검하기 때문에 꽤 많은 시간을 잡아먹는다. 오라클에서는 기업용 드라이브의 경우 최소 1달에 한 번, 일반 드라이브의 경우 최소 1주에 한 번씩 scrub을 진행하는 것을 권장한다.
scrub 명령은 빠른 256비트 알고리즘인 fletcher4를 써서 체크섬을 검사한다. 물론 SHA-256 알고리즘을 쓰도록 지정할 수 있지만, fletcher4보단 속도가 느림을 주의해야 한다. 물론 해시 함수의 특성 상 체크섬 검사가 틀릴 확률은 있다. 단, 2^256회의 검사중 한 번. 이를 소수로 표현하면 0.00000000000000000000000000000000000000000000000000000000000000000000000000001%이다. 참고로 시장에서 가장 신뢰성 높은 Non-ECC RAM 기준으로, 메모리 에러 발생률은 저것보다 50배 더 빈도가 높다. 그 정도로 몹시 낮은 확률이므로 안심하자.
단점
ZFS는 위에서 보았듯 현존하는 파일 시스템의 최종 보스라고 볼 수 있는 존재지만, 그렇다고 해서 장점만이 존재하는 것은 아니다.
서버용 장비 권장, ECC 메모리 권장, 높은 램 점유율, 디스크 단편화로 인한 성능 저하 등 이 있다.
- Ref.
https://constantin.glez.de/2010/07/20/solaris-zfs-synchronous-writes-and-zil-explained/index.html