정의
단일 처리 시스템에서는 실행 중인 프로세스(A)가 존재하는데 다른 프로세스(B)가 입출력을 요청하면 그 프로세스(B)는 이전의 프로세스(A)의 자원을 놓을때까지 대기하고 있어야합니다. 하지만 다중 프로그래밍에서는 여러 프로세스들이 동시에 돌아갈 수 있으며, 프로세스가 자원(프로세서 등)을 요청하면 운영체제는 그 자원을 적절히 분배하여 프로세스에게 할당합니다.
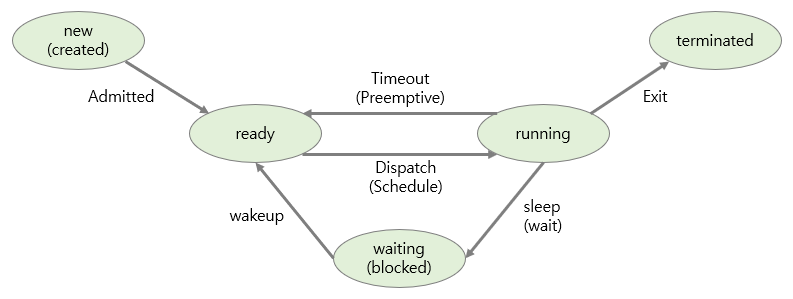
new : 새로 생성된 상태
ready : CPU를 할당받기 위해 Ready List에서 기다리는 상태
running : CPU를 할당받아 실행중인 상태
waiting : 입출력 처리나 이벤트가 끝날 때까지 Waiting List에서 기다리는 상태
terminated : 모든 수행이 종료된 상태
| 전이(Transition) | 상태(State) 변화 | 설명 |
|---|---|---|
| admitted | new→ready | 생성된 프로세스가 메모리로 올라옴 |
| dispatch (=schedule) | ready→running | Ready List 내 프로세스 중 우선순위에 따라 한 프로세스에 CPU 할당 |
| timeout (=preemptive) | running→ready | 주어진 타임 슬라이스를 다 사용하였거나 우선순위가 높은 프로세스에 의해 선점 당함 |
| sleep (=wait) | running→waiting | 입출력 처리나 이벤트가 발생하여 프로세스가 스스로 CPU 반납 후 Waiting List로 이동 |
| wakeup | waiting→ready | 기다리던 입출력 처리나 이벤트가 종료되어 Ready List로 이동 |
| exit | running→terminated | 프로세스가 running 상태에서 할 일을 모두 끝냄 |
- 스케줄링 메트릭스 (Scheduling Metrics)
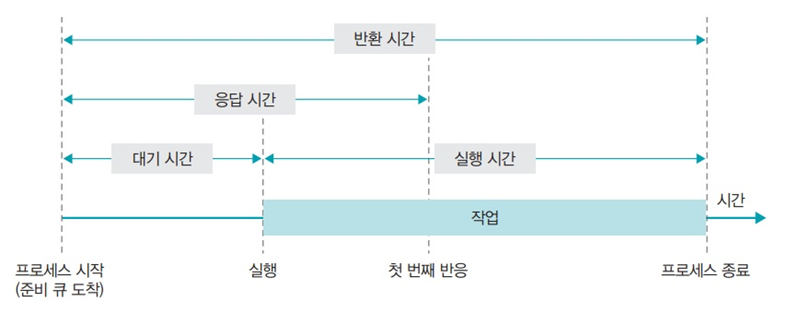
| 용어 | 설명 |
|---|---|
| 대기 시간 | 자원의 할당을 대기하는 시간을 의미합니다. |
| 실행 시간 | 실제로 프로세스가 자원을 할당받은 다음 작업을 수행하는 시간을 의미합니다. |
| 반환 시간 | 작업을 완료하는데 소요되는 전체 시간으로 대기 시간과 실행 시간을 모두 포함합니다. |
- 스케줄링 정책
사용중인 CPU를 뺏을 수 있는지, 없는지로 스케줄링 정책이 구분된다.
(1) 비선점형 스케줄 (Non-Preemptive Scheduling)
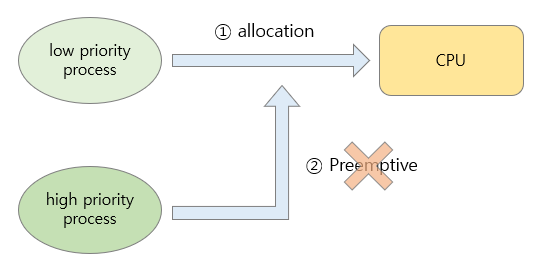
한 번 CPU를 할당 받은 프로세스는 작업이 종료될 때까지 CPU를 독점한다. 해당 프로세슥 종료되기 전까지는 다른 프로세스가 CPU를 사용할 수 없다.
(2) 선점형 스케줄링 (Preemptive Scheduling)
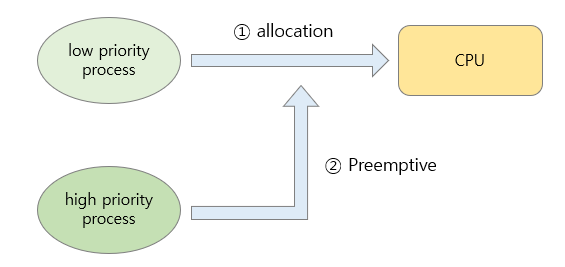
프로세스A가 CPU를 사용하고 있더라도, 그것보다 우선순위가 높은 프로세스B가 CPU를 뺏을 수 있다. 즉, 기존 프로세스를 중단시켜 CPU를 반납하게 한 후, 우선순위가 높은 프로세스가 CPU를 할당 받아 수행될 수 있다. 이때 문맥 교환이 발생한다.
| 구분 | 비선점형 스케줄링 | 선점형 스케줄링 |
|---|---|---|
| 장점 | 모든 프로세스를 공평하게 처리한다. | 응답시간이 빠르다 |
| 단점 | 작업 시간이 짧더라도, 긴 작업 시간을 가진 프로세스가 끝날 때까지 대기해야 한다. | 문맥 교환이 과하게 발생하면 오버헤드가 발생한다. |
| 알고리즘 | FCFS, SJF, HRN 등 | SRT, RR, MLFQ 등 |
| 활용 | 프로세스 간 작업 시간이 비슷한 환경 | 실시간 응답 환경 |
1. 선입선처리 스케줄링(First Come First Served, First In First Out)
선입선처리(FCFS, FIFO) 알고리즘은 말 그대로 먼저 요청한 프로세스가 먼저 리소스를 제공받으며 이미 사용중이라면 사용이 끝날때까지 기다려야하는 스케줄링 방식입니다.
| 프로세스 | 도착 시간 | 실행 시간 |
|---|---|---|
| P1 | 0 | 10 |
| P2 | 1 | 28 |
| P3 | 2 | 6 |
| P4 | 3 | 4 |
| P5 | 4 | 14 |
먼저 요청한 프로세스가 먼저 제공받으니 P1부터 차례대로 리소스를 할당받습니다. 그래서 프로세스의 반환시간과 대기시간을 구하면 아래와 같습니다.
| 프로세스 | 반환시간 | 대기시간 |
|---|---|---|
| P1 | 10 | 0 |
| P2 | 37 | 9 |
| P3 | 42 | 36 |
| P4 | 45 | 41 |
| P5 | 58 | 44 |
| 평균 | 평균 반환 시간 (10+37+42+45+58)/5 = 38.4 | 평균 대기 시간 (0+9+36+41+44)/5 = 26 |
장점
1) 스케줄링이 단순합니다.
2) 모든 프로세스가 실행될 수 있습니다.
3) 프로세서가 지속적으로 유용한 프로세스를 수행하여 처리율이 높습니다.
단점
1) 비선점방식의 스케줄링이므로 대화형 작업에는 부적합합니다.
2) 만약 어떤 프로세스의 수행시간이 길면 대기시간이 늘어납니다. 그래서 짧고 간단한 작업은 계속 기다려야합니다.
2. 최소 작업 우선 스케줄링(Shortest Job First)
프로세스의 실행 시간을 이용하여 가장 짧은 시간을 갖는 프로세스가 먼저 리소스를 할당받는 방식입니다. 이 방식은 선점할 수도 있는 스케줄링 방식입니다. 이전에 FIFO방식은 중간에 다른 프로세스가 들어오면 그 프로세스는 대기해야했죠? 이 스케줄링 방식은 선점 또는 비선점이 가능합니다.
| 프로세스 | 반환시간 | 실행 시간 |
|---|---|---|
| P1 | 10 | 0 |
| P2 | 61 | 33 |
| P3 | 18 | 12 |
| P4 | 11 | 7 |
| P5 | 30 | 16 |
| 평균 | 평균 반환 시간 (10+61+18+11+30)/5 = 26 | 평균 대기 시간 (0+33+12+7+16)/5 = 13.6 |
P1이 먼저 요청해서 자원을 할당받아 놓은 상태인데, P2가 도착합니다. 비선점형이기 때문에 P2는 우선 기다리고 있는데 P1의 작업이 끝나기 전에 P3, P4 ,P5의 요청이 도착하네요. 그러면 실행 시간이 가장 작은 P4가 자원을 할당받아 쓰고 그 다음인 P3이 자원을 할당받아 사용합니다. 이렇게 되면 위와 같은 결과가 도출되지요.
그렇다면 비선점형 SJF는 어떨까요? 아래의 표가 선점형 SJF의 결과입니다.
| 프로세스 | 반환시간 | 실행 시간 |
|---|---|---|
| P1 | 20 | 10 |
| P2 | 61 | 33 |
| P3 | 10 | 5 |
| P4 | 4 | 0 |
| P5 | 30 | 16 |
| 평균 | 평균 반환 시간 (20+61+10+4+30)/5 = 25 | 평균 대기 시간 (10+33+4+0+16)/5 = 12.6 |
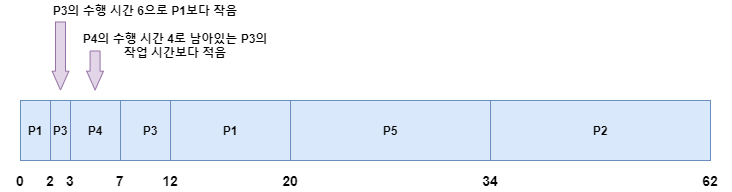
이해를 돕기 위해서 아래의 간트 차트를 보세요. P1이 먼저 도착해서 수행하고 있는 와중에 P2가 도착하는데요. P2는 수행되어야할 시간이 P1보다 크니 P1은 계속 작업을 수행합니다. 그러다가 P3가 도착하는데 P1이 수행해야할 시간보다 P3의 수행시간이 더 짧으니 P3가 작업을 수행합니다. 그런데 P4가 다음에 도착하네요. P4가 더 적은 시간을 갖으니 P4를 수행합니다. 이때 P4가 끝나면 남아있는 프로세스 중에서 가장 적은 수행시간을 갖는 P3의 작업을 이어서 하게 됩니다.
장점
1) 항상 짧은 작업을 먼저 처리하게 되니까 평균 대기시간이 가장 짧습니다.
단점
1) 수행시간이 긴 작업은 짧은 작업에 밀려 기아가 발생합니다.
2) 실행 시간을 예측할 수 없어 실용적이지 못합니다.
3) 짧은 작업이 먼저 실행되므로 공정하지 못한 정책입니다.
3. 우선순위 스케줄링(Priority)
우선순위 스케줄링은 프로세스마다 우선순위라는 속성이 붙게 됩니다. 우선순위 스케줄링도 역시 선점, 비선점형으로 스케줄링이 가능합니다. 숫자가 높을 수록 우선순위가 높고 만약 우선순위가 같다면 FIFO방식으로 동작합니다.
| 프로세스 | 도착 시간 | 실행 시간 | 우선순위 |
|---|---|---|---|
| P1 | 0 | 10 | 3 |
| P2 | 1 | 28 | 2 |
| P3 | 2 | 6 | 4 |
| P4 | 3 | 4 | 1 |
| P5 | 4 | 14 | 2 |
그래서 아래는 선점형에서의 결과를 나타낸 표입니다. 약간 헷갈릴 수 있을텐데요. P1 먼저 수행하다가 P3가 오면 우선 순위가 P3가 더 높으니까 P1은 대기하고 P3가 작업을 수행합니다.
| 프로세스 | 반환시간 | 실행 시간 |
|---|---|---|
| P1 | 16 | 6 |
| P2 | 43 | 15 |
| P3 | 6 | 0 |
| P4 | 59 | 55 |
| P5 | 54 | 40 |
| 평균 | 평균 반환 시간 (16+43+6+59+54)/5 = 35.6 | 평균 대기 시간 (6+15+0+55+40)/5 = 23.2 |
다음은 비선점형일때의 결과 표입니다.
| 프로세스 | 반환시간 | 실행 시간 |
|---|---|---|
| P1 | 10 | 0 |
| P2 | 43 | 15 |
| P3 | 14 | 8 |
| P4 | 59 | 55 |
| P5 | 54 | 40 |
| 평균 | 평균 반환 시간 (10+43+14+59+54)/5 = 36 | 평균 대기 시간 (0+15+8+55+40)/5 = 23.6 |
만약 우선순위가 낮은 프로세스가 높은 프로세스에 의해 실행이 되고 있지 않은 상황이라면 어떻게 될까요? 이때는 그 프로세스의 우선순위를 점차 높여 처리받게끔 하는 에이징이라는 기법을 사용합니다.
장점
1) 각 프로세스의 중요성에 따라서 작업을 수행하기 때문에 합리적입니다.
2) 실시간 시스템에서 사용가능합니다.
단점
1) 높은 우선순위를 갖는 프로세스가 계속적으로 스케줄링이 되면 우선순위가 낮은 프로세스는 자원을 할당받지 못하기 때문에 기아가 발생할 수 있습니다.
4. 라운드 로빈 스케줄링(Round-Robin)
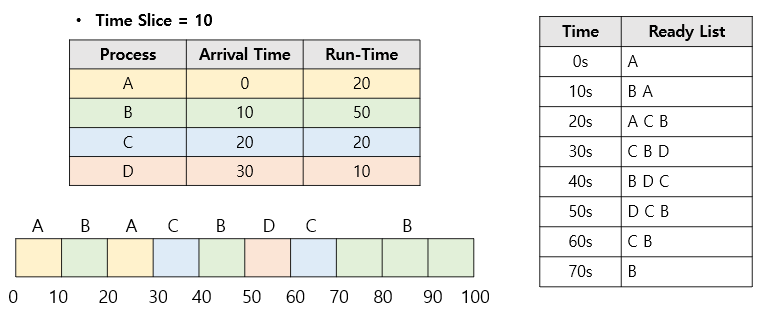
라운드 로빈 스케줄링은 시분할 시스템을 위해 설계된 스케줄링 기법입니다. 이 스케줄링은 작은 단위의 시간인 시간 할당량(Time-Slice)을 정의하여 그 시간 만큼 자원을 할당하는 방식입니다. 그래서 그 시간안에 작업을 끝내지 못하면 다음 프로세스가 다시 그 시간만큼 자원을 할당받아씁니다. 여기서 시간 할당량을 5로 정하고 간트 차트와 결과를 보면 아래와 같습니다.
각 프로세스들은 공정하게 5만큼의 시간 동안 작업을 진행하는 것을 볼 수 있네요.

| 프로세스 | 반환시간 | 실행 시간 |
|---|---|---|
| P1 | 29 | 19 |
| P2 | 61 | 33 |
| P3 | 33 | 27 |
| P4 | 16 | 7 |
| P5 | 45 | 31 |
| 평균 | 평균 반환 시간 (29+61+33+16+45)/5 = 36.8 | 평균 대기 시간 (19+33+27+7+31)/5 = 23.4 |
장점
1) 모든 프로세스가 공정하게 스케줄링을 받을 수 있습니다.
2) 실행 큐에 프로세스의 수를 알고 있을때 유용합니다.
3) 프로세스의 짧은 응답시간을 갖고 최악의 응답시간을 알 수 있습니다.
4) 평균 대기시간이 FIFO와 SJF보다 적습니다.
단점
1) 성능은 규정 시간량의 길이에 따라 달라지므로 작업이 비슷한 길이가 좋은데, 너무 길면 FIFO로 변하고 짧으면 문맥 교환(Context Switching) 비용이 증가합니다.
2) 하드웨어적 타이머가 필요합니다.
3) 미완성 작업은 규정 시간량(시간 할당량)을 마친 후 프로세서를 기다리니까 평균 처리 시간이 높습니다.
5. SRTF 스케줄 (Shortes Remaining Time First)
SRTF는 잔여 CPU burst가 가장 적은 프로세스를 선택한다. SRTF는 SJF의 preemptive version이다. 프로세스의 Ready Queue에는 도착시간이 명시되어야 한다. 프로세스 수행중 다른게 Ready Queue에 들어오면 잔여시간을 계산하여 어떤 것을 먼저 수행할지 결정한다.
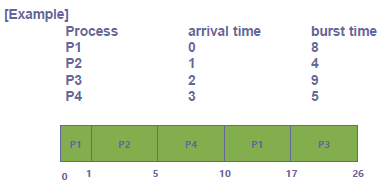
프로세스 P1, P2, P3, P4 순서로 도착했다고 하자.
t=1, 그럼 P1먼저 수행될 것이고 P2가 도중에 도착할 것이다. 그럼 이때 잔여시간을 비교한다. P1의 잔여시간은 8-1=7이고 P2의 잔여시간은 4이므로 P2가 선택되어 수행된다.
t=2, P2 수행중 P3가 도착할 것이고 레디큐의 모든 프로세스의 잔여시간을 계산한다. P1의 잔여시간 7, P2의 잔여시간 3, P3의 잔여시간 9로 P2가 선택된다.
t=3, P4가 도착한다. 2번과 같이 잔여시간을 계산한다. P1: 7, P2: 2, P3: 9, P4: 5. P2가 선택되어 P2가 계속 수행된다.
t=5, P2가 끝나고 잔여시간을 계산한다. P1: 7, P3: 9, P4: 5. P4가 선택되고 계속 수행된다.
t=10, P4가 끝난다. P1이 선택되고 계속 수행된다.
t=17, P1이 끝난다. P3가 선택되고 계속 수행된다.
따라서 대기시간(시작시간-도착시간)은 순서대로 9, 0(P2는 들어오자마자 수행됨), 15, 2이다. 평균 대기시간은 6.5이다.
6. HRN (Highest Response Ratio Next)
SJF에서 기아 상태라는 단점을 해결하기 위한 알고리즘으로, Response Ratio가 큰 긴 프로세스에 높은 우선순위를 부여한다. 즉, 대기시간이 긴 프로세스의 우선순위를 높임으로써 기아 상태를 방지한다.
ResponseRatio=(대기시간+작업시간)/작업시간
장점 : 작업 시간이 긴 프로세스와 짧은 프로세스 간 불평등을 어느 정도 해소한다. SJF의 기아 상태를 최소화한다.
단점 : 각 프로세스의 작업 시간을 계속 추적해야 하므로 오버헤드가 발생한다.

| 프로세스 | 반환 시간 | 응답 시간 |
|---|---|---|
| A | 20 - 0 = 20 | 0 - 0 = 0 |
| B | 50 - 10 = 40 | 20 - 10 = 10 |
| C | 80 - 20 = 60 | 60 - 20 = 40 |
| D | 60 - 30 = 30 | 50 - 30 = 20 |
| 평균 | 37.5 | 17.5 |
- Ref.
https://www.tutorialspoint.com/operating_system/os_process_scheduling_algorithms.htm
https://www.geeksforgeeks.org/cpu-scheduling-in-operating-systems/